
July 2023 Update: Currently, I am in the process of utilizing ChatGPT to enhance the search engine’s performance. Stay tuned.
Over the past decade, there has been a significant growth in computational power, digital storage capacity, and innovative network protocols. This technological progress has led to the accumulation of vast corpora of written documents on the internet. These repositories encompass a wide range of data, including source-code repositories, literature, scientific papers, and more. The abundance of semi-structured textual data available on the web presents a valuable resource for extracting knowledge for educational and industrial applications.
These repositories serve as free and accessible reservoirs of information that can be harnessed for various purposes. Researchers, educators, and professionals can leverage this wealth of data to extract valuable insights, conduct in-depth analyses, and foster innovation across different domains. The availability of such vast and diverse textual data has opened up new opportunities for natural language processing, information extraction, and text mining techniques, allowing us to make sense of the vast amount of information available on the web. As a result, these repositories have become invaluable sources of knowledge, contributing to the advancement of science, technology, and numerous other fields.
Github example
Indeed, Github stands as a prominent and vast example of such free corpora, where millions of commits from thousands of developers are readily accessible. Given the cost-free access to this data, it’s only a matter of time before companies and organizations begin to develop Information Extraction engines to extract crucial features related to software development.
By applying Information Extraction techniques to Github data, companies can uncover valuable insights about developers’ expertise, coding habits, and behavioral patterns. This wealth of information can be utilized to categorize and sort developers based on their skills, contributions, and coding practices. Such insights can be instrumental in identifying top talent, understanding the dynamics of developer communities, and even predicting potential software issues or security vulnerabilities.
Moreover, the ability to extract relevant features from Github data has the potential to enhance collaboration, foster knowledge-sharing, and drive innovation within the software development community. This data-driven approach can aid in optimizing team structures, identifying areas for skill development, and promoting best coding practices.
In summary, the extraction and analysis of critical features from Github data can offer tremendous value to businesses, researchers, and developers alike. It opens up a new realm of possibilities for talent identification, community engagement, and advancing software development practices.
Blockchain technology
Blockchain technology stores a significant amount of information in a decentralized and secure manner. Extracting and utilizing this data involves leveraging various techniques to access and analyze the data stored on the blockchain. Textual Information Extraction techniques can be applied to public blockchains to extract valuable insights and knowledge.
The rising era of blockchain-based data repositories offers several advantages for Information Extraction:
- Data Integrity: The data stored on the blockchain is immutable, ensuring its integrity and making the outputs of Information Extraction more trustworthy.
- Incentive for Clean Data: Since individuals have paid to store data on the blockchain, there is a strong collective incentive to keep the documents clean, functional, and accurate.
When considering the two most famous blockchains, Bitcoin and Ethereum:
- Bitcoin: It primarily serves as an append-only ledger for tracking transactions. While there are limited scripting capabilities within the Bitcoin ecosystem, the majority of the ledger consists of a sequential chain of transactions. The information to be extracted from the Bitcoin ledger mainly revolves around transaction properties and analyzing complex transaction graphs.
- Ethereum: In contrast, Ethereum’s blockchain is built around smart contracts, which are written in Solidity and available for auditing. Solidity language is designed to be human-readable, encouraging developers to maintain clean and unambiguous code, including meaningful variable and function names. As a result, a corpus of Ethereum Smart Contracts proves to be an excellent candidate for applying standard Information Extraction techniques.
Overall, the utilization of Information Extraction techniques on public blockchains, especially Ethereum, holds immense potential for gaining insights, auditing smart contracts, and extracting valuable data in a trustworthy and secure manner.
What is Ethia?
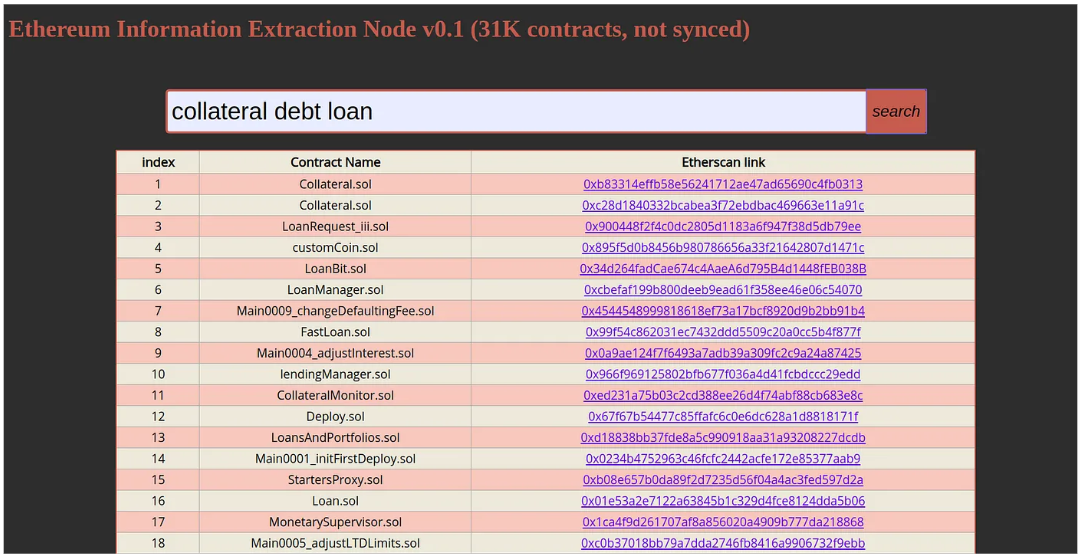
Ethia v0.1 marks my initial endeavor to extract information from publicly available smart contracts. In essence, it serves as a search engine that finds the most similar smart contracts based on user-entered queries. Fig. 2 illustrates the pilot front-end of the current version, where a collection of words has been inputted around a specific topic, and the search engine returns the 50 most similar contracts from a pool of 31,000 Mainnet preprocessed smart contracts.
Now, let’s delve into the workings under the hood:
To analyze a set of human-generated textual documents, Natural Language Processing (NLP) techniques are employed. The NLP process involves an iterative pipeline of extractions, cleansing, and measurements over textual content to uncover hidden relationships among informative data pieces and aggregate knowledge for more sophisticated tasks. In [1], Adam Geitgey outlines the typical steps of the NLP pipeline and provides Python script samples for implementation.
As mentioned earlier, for the Smart Contract Information Extraction engine, we only require a few basic steps. Ethia currently follows these four main stages:
- Dumping: Solidity smart contract codes are extracted using the Smart Contract Sanctuary [2], an open-source script that retrieves the solidity smart contracts from Etherscan and Etherchain websites.
- Structural preprocessing: The ConsenSys Python Solidity AST Parser [3], another open-source script, is employed to generate Abstract Syntax Trees (ASTs) of the dumped smart contracts. These ASTs are stored in a NoSQL database (MongoDB) for later nested searches.
- Natural Language preprocessing: Traversing the abstract syntax trees, a straightforward and simple NLP pipeline is used to extract meaningful words from function names and variable names that developers use to express the functionality of different parts of the code. The steps in this process include Segmentation, StopWord Removal, Stemming, and Name Entity Recognition. From the extracted words, a Bag-of-Word model of contracts and a TF-IDF (Term Frequency Inverse Document Frequency) metric are generated, along with an overall dictionary of all used words.
- Calculating Similarity: The cosine similarity of the entered query (after simple preprocessing) is calculated over the contracts’ TF-IDF representations. A sorted list of contracts is then presented to the user based on this similarity calculation.
Related works
Various Information Extraction studies have been designed to cater to different contexts. For example, the LexNLP library [4] is a fully implemented example of an Information Extraction pipeline that works on legal and regulatory corpus. In [5], Adnan et al. proposed a generic information extraction system that can leverage other data types, such as visual resources. These studies typically deal with unstructured documents. However, in our case, the Solidity syntax and the developers’ incentive result in smart contracts that are almost fully structured. This makes information extraction tasks less expensive and more accurate for us.
Conclusion
Ethia v0.1 represents an ambitious effort to leverage freely available smart contracts for searching within the realm of currently developed source codes. It serves as a valuable tool, especially for beginner solidity developers like myself, facilitating the exploration of code patterns related to arbitrary topics. Through this platform, developers can efficiently navigate and learn from existing smart contracts, accelerating their understanding and proficiency in Solidity programming.
References
[1] https://medium.com/@ageitgey/natural-language-processing-is-fun-9a0bff37854e
[2] https://github.com/tintinweb/smart-contract-sanctuary/tree/master/utils
[3] https://github.com/ConsenSys/python-solidity-parser
[4] https://github.com/LexPredict/lexpredict-lexnlp
[5] Adnan, K., Akbar, R. An analytical study of information extraction from unstructured and multidimensional big data. J Big Data 6, 91 (2019). https://doi.org/10.1186/s40537-019-0254-8

